A major release for the Canonical GTFS Schedule Validator
The Canonical GTFS Schedule Validator v3.0 release contains many fixes, new features and improvements to the documentation.
In 2020, MobilityData released its Canonical GTFS Schedule Validator, which has already been used by many stakeholders in the industry. We’re happy to bring you the v3.0 release of the Canonical GTFS Schedule Validator, it’s a big one! This release packs in a mountain of fixes, new features and improvements to the documentation. Thanks to our contributors!

Let’s walk through it together to discover the most important changes implemented with this release, and how it contributes to improving data quality and as a result, the lives of billions of public transit travelers.
Need a reminder about why we built that tool? Read this informative link.
Since this blog post is quite technical; here is a quick overview of what you need to know from this major release:
- We did a thorough analysis, we then added 25 new rules in the validator, and modified 4 existing ones.
- The v3.0 release uses real GTFS feeds from the Mobility Database to test the code, ensuring stability for GTFS producers and consumers.
- We ran the Canonical GTFS Schedule Validator v3.0 on the 1245 public datasets available on the Mobility Database. Constructive results!
Impacting the public transit journey of millions of people, we are proud to see that this validator is internationally used by trip planning apps such as Google Maps and Transit, along with government agencies such as the State of California (Cal-ITP) and the French national access point.
☑️ A more complete version that reflects practice
The Canonical GTFS Schedule Validator has been originally built using the code base of Google’s transitfeed validator, which already contained validation for the majority of the files described in GTFS.
Over the last year, we went through the GTFS specification and mapped what parts were being checked by one of the validator rules, noting discrepancies and parts that weren’t checked at all.
From this analysis, we then added 25 new rules in the validator, and modified 4 existing ones.
There is now validation for the latest GTFS-extensions that were adopted in the specification (pathways.txt, levels.txt and attributions.txt), and also a handful of more complex rules, such as:
- making sure all locations in a station that has pathways implemented are reachable at least in one direction (PathwayUnreachableLocationNotice)
- informing that a stop has many potential matches to the trip’s shape (StopHasTooManyMatchesForShapeNotice)
- informing that a stop isn’t used in any trip (StopWithoutStopTimeNotice)
- informing that the vehicle moves too fast between two stops (FastTravelBetweenConsecutiveStopsNotice)
We also took this opportunity to loosen up parts of the specification to reflect practice, as the GTFS specification was being reviewed to comply with RFC 2119. As a result, we downgraded two validator rules:
👍 Less invalid additions
Because this tool aims at being used directly in different pipelines, it needs to be stable. If a new rule is added and makes, for example, the New York City subway GTFS feed “invalid”, this data could disappear from a trip planning app that is relying on this tool.
The v3.0 release uses real GTFS feeds from the Mobility Database to test the code, ensuring stability for GTFS producers and consumers.
This is why we added a test that is able to inform a developer if a new rule added to the validator results in additional errors on any dataset from the Mobility Database. This test will run automatically and the result will be critical in deciding whether to add a new rule or not. A report will be displayed to the developer for further analysis, because this could also mean that there might be a problem with the code (sample report below). The dataset ID’s here are the ID’s of the Mobility Database.

Depending on the number of datasets that could become invalid with a new rule, we will decide with the community if a severity should be set as a “warning” for a fixed period in order to let the GTFS producers have a chance to fix their feeds.
📈 What we learned from running the validator on industry feeds
As of today we have 1245 datasets from all around the world that are publicly available on the Mobility Database. Here are the results we got from running the validator on all of them.
The most common problems found in GTFS feeds
The first thing we looked at was the number of different issues that were found by the validator.
There are 86 different types of problems that the validator can detect in total, ranging from issues with parsing the data, missing files and fields, a field type that isn’t respected, or more complex problems like checking vehicle speed or pathway design.
On the 1245 datasets, only 54 types of issues were found over the 86 that the validator looks at. We then looked more in detail into what were the most common issues found in datasets.
The validator defines two different types of issues:
- “Error” is for items that the GTFS specification explicitly requires or prohibits (e.g., using the language “must”). Those make a dataset “valid” or “invalid” with regard to the official specification.
- “Warning” is for items that will affect the quality of GTFS datasets but the GTFS spec does not expressly require or prohibit. For example, these might be items recommended using the language “should” or “should not” in the GTFS spec, or items recommended in the MobilityData GTFS Best Practices.
The chart below shows the most common errors that were found. Note that here, a specific error will be counted as “one” if present in a dataset, regardless of the number of times it’s present. Details on these issues can be found in validator’s GitHub repository in RULES.md.
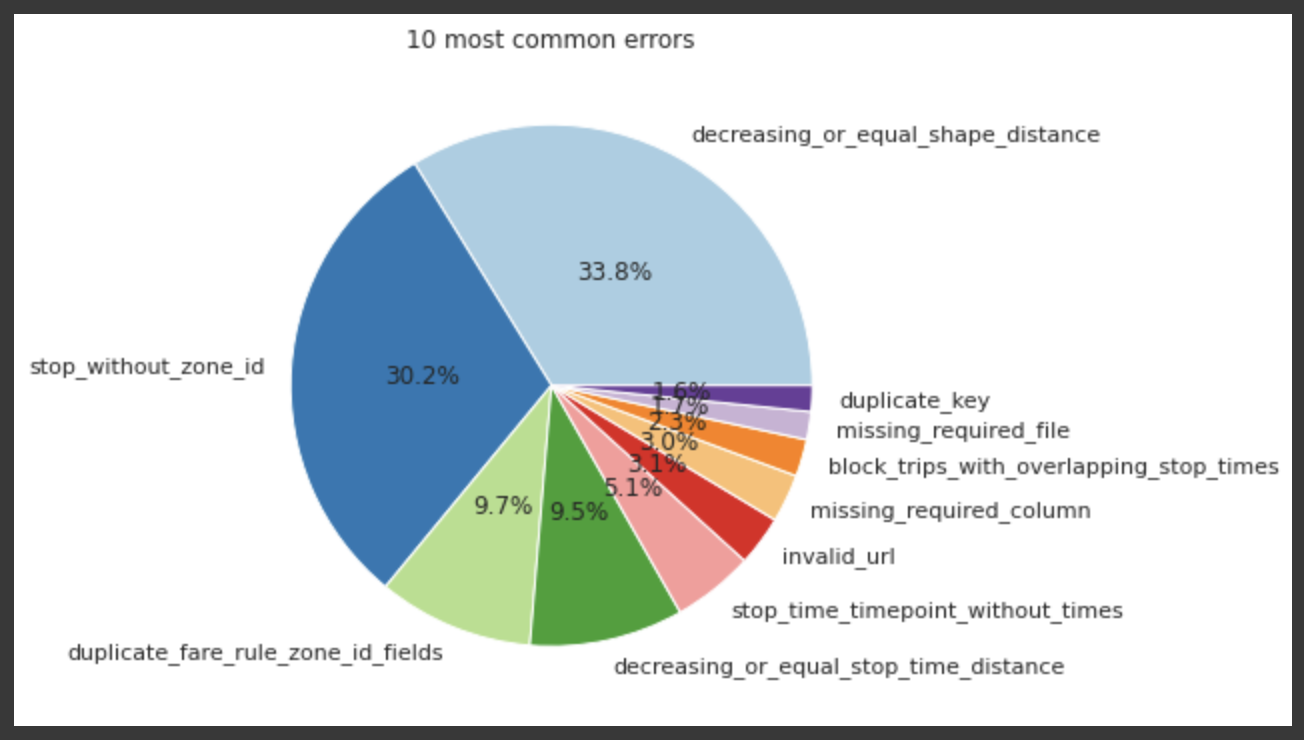
We can see here that decreasing_or_equal_shape_distance and stop_without_zone_id are by far the most present. After investigation, we realized that the validator’s behaviour for those two rules might be stricter than the official specification and further analysis should be done to evaluate if the code needs to be loosened.
The chart below shows the most common warnings found.

How much of the data is valid?
The second thing we looked at was the proportion of datasets that have some problems versus the ones that don’t. The graph below shows the proportion of datasets containing errors, and the proportion containing warnings.
A good proportion of datasets do not contain any errors, 🎉 kudos to data producers!
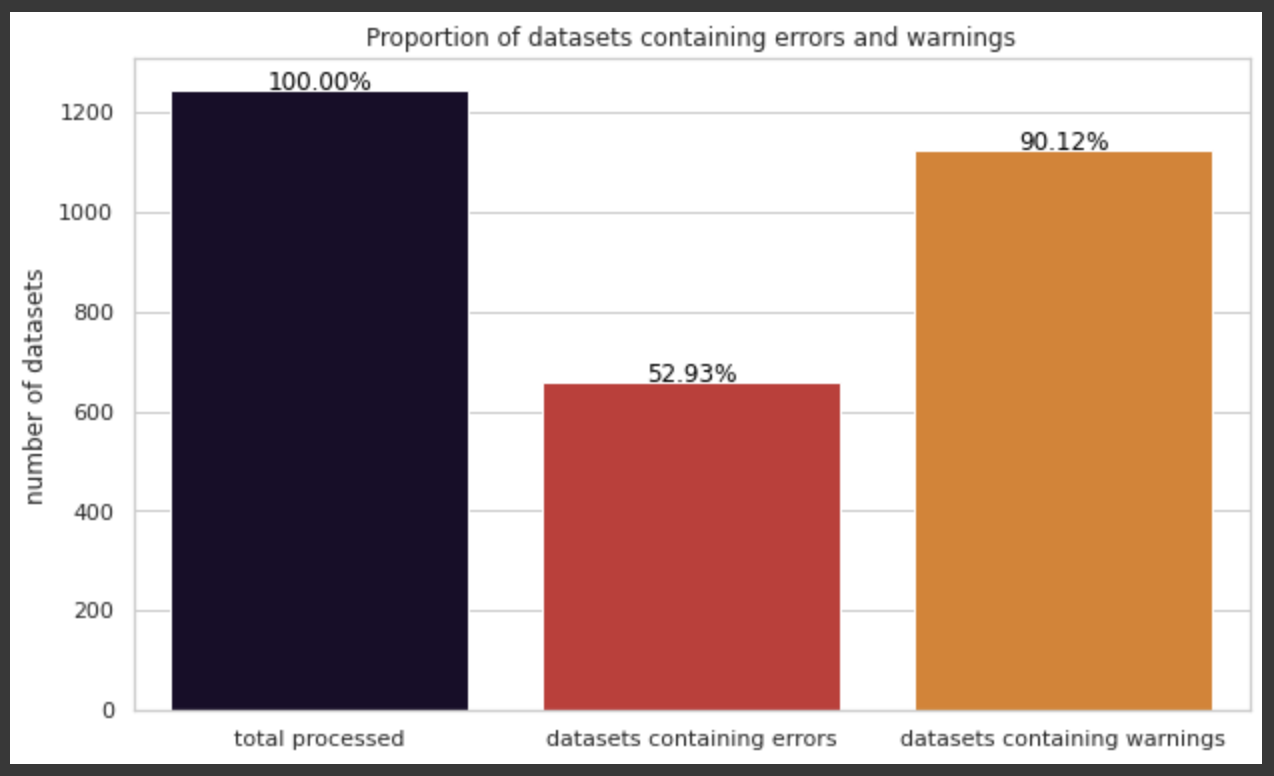
We estimate that after we investigate potential false positives for decreasing_or_equal_shape_distance and stop_without_zone_id, the percentage of invalid datasets could decrease to 25%.
⏭️ What’s next?
Our team is now tackling the next challenge: adding customization in the validation sets.
Why? Because the GTFS specification isn’t the only set of rules our users want to validate against.
Our users want to be able to validate GTFS extensions (like GTFS-Flex or GTFS-Fares) before they get officially adopted because they are using it. Some GTFS consumers have additional criteria and they would like to be able to add them to the validator.
We would love to hear from you.
🛠️ If you’re interested in contributing to the Canonical GTFS Schedule Validator, please get in touch with isabelle@mobilitydata.org.
💬 Please share your feedback and use cases in our 3.1.0 Release plan issue or in our Public Roadmap so you help us build exactly what you need!



